Pengenalan Kepada AI, ML & DL
Perbincangan berkenaan Artificial Intelligent, Machine Learning dan Deep Learning.
Salam semua. Kita selalu mendengar perkataan “Artificial Intelligent” atau “AI”. Kalau masa awal-awal dulu kita rasa kembang hidung bila dapat mengguna perkataan ini dalam perbualan atau pun ceramah kita. Tapi, adakah setakat tahu menyebutnya sahaja sudah cukup? Tidak kah teringin untuk mengetahuinya dengan lebih mendalam? Ya, saya mahu! Anda bagaimana? Mari kita lakukan sedikit kajian. Maklumat di hujung jari anda!
Selain daripada AI, mungkin juga anda pernah dengar terma Machine Learning (ML) atau Deep Learning (DL) kan. Sejak kebelakangan ini kerap sangat kita dengar tiga perkataan ini sinonim dengan terma Data Science lah Data Analytic lah kan? Di sini saya nak bincangkan berkenaan tiga terma yang popular ini. Apa bendanya AI, ML, dan DL ni? Ahh zaman sekarang ni apa pun google jer.
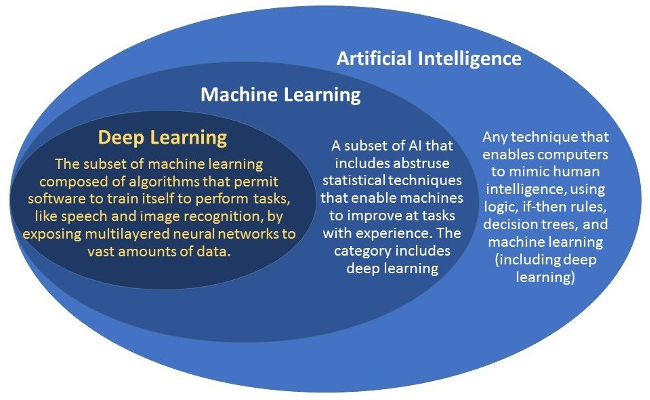
Ohh! DL adalah subset ML dan subset AI. AI dalam bahasa melayunya “kecerdasan buatan” boleh dicapai melalui pelbagai teknik. ML adalah salah satu tekniknya yang popular di masa kini. Manakala DL adalah salah satu teknik algoritma ML yang sedang hangat diperkatakan. Selain DL ada banyak lagi algoritma-algoritma lain yang popular seperti SVM, XGBoost, Random Forest yang sangat bagus untuk data yang tersusun dalam bentuk tabular data atau pun database. DL pula sangat berkuasa untuk menyelesaikan isu berkaitan “perceptual problem” seperti data yang berkaitan dengan imej, video, suara, dan bahasa.
Secara teorinya semakin banyak input data yang berkualiti dibekalkan, semakin baik prestasi outputnya. Namun, Gambarajah di bawah menunjukkan, prestasi algoritma tradisional seperti SVM, Random Forest, XGBoost akan mencapai takat tepu mendatar walaupun bekalan data yang di sumbat masuk semakin banyak. Sebaliknya, prestasi NN pula di lihat boleh ditingkatkan sejajar dengan jumlah input data yang semakin banyak.
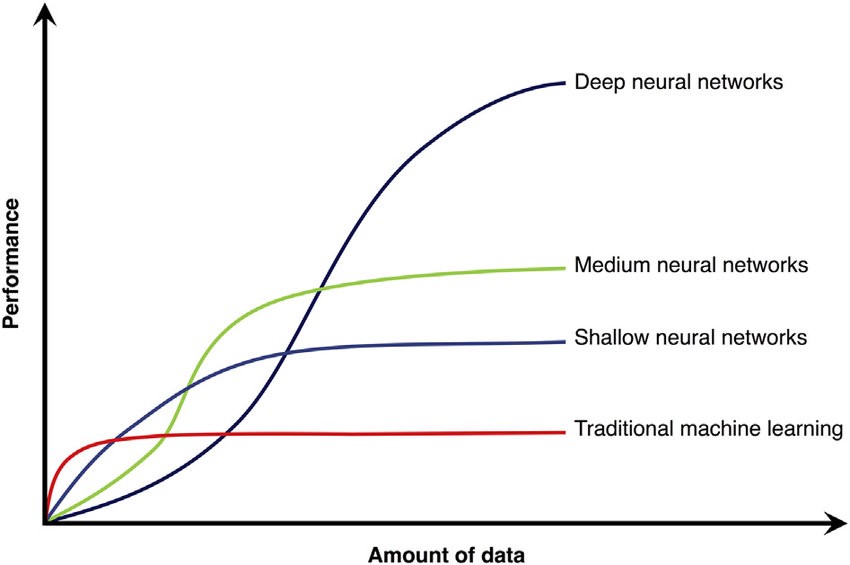
Ehh sekejap, ini algoritma NN (Neural Network), bukan DL (Deep Learning)!
Pada yang tidak tahu, DL ini adalah nama branding terkini untuk NN yang di pelopori oleh Bapa Deep Learning, Geoffry Hinton. Apa tu Neural Network? mungkin anda tertanya-tanya kan. Takpa itu letak di tepi dulu, cuba lihat gambarajah di bawah.
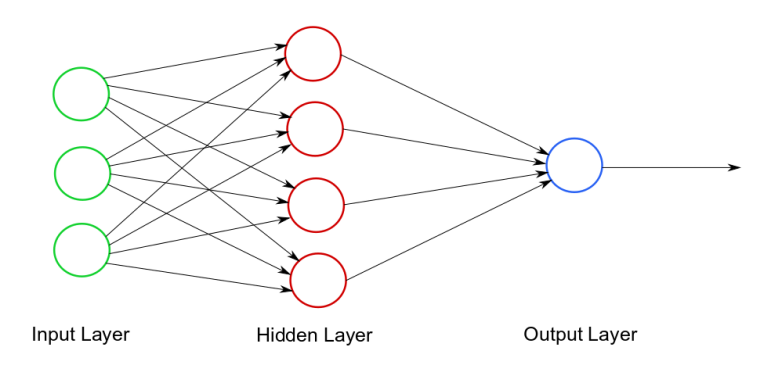
Gambarajah architecture NN ini terdiri daripada 3 lapisan, iaitu:-
- Lapisan Pertama, Input Layer beserta 3 node atau feature
- Lapisan Kedua, Hidden Layer beserta 4 node atau feature
- Lapisan Ketiga, 1 Output node.
Ini merupakan contoh architecture asas NN yang sekarangnya dipanggil Shallow NN. Pada masa dahulu lebih kurang pada tahun 1950 - 1960, architecture Shallow NN sahaja lah yang mampu di capai, namun kemudiannya idea NN ini terkubur berdekad-dekad lamanya (kita akan bincangkan sejarah DL kemudian). Kini, architecture NN boleh di bina dengan lebih Deep, jumlah node dan lapisan yang lebih banyak dan kompleks. Secara teorinya semakin banyak node dan lapisan architecturenya maka semakin tinggi lah kerumitan masalah yang ia boleh selesaikan, tetapi semakin tinggi pula kuasa pemprosesan yang diperlukan.
Ok. Sebelum kita menjebakkan diri ke dalam dunia DL, kenali ML terlebih dahulu.
Machine Learning
Machine learning jika diterjemahkan secara terus kepada bahasa melayu apa maksudnya? Mesin Belajar? Belajar Mesin? atau mungkin lebih tepat jika ia bermaksud mesin yang boleh di ajar. Mesin yang satu hari nanti boleh mengajar "diri"nya sendiri mungkin kedengaran menakutkan ataupun kelakar, tetapi menurut Elon Musk, jika penggunaan teknologi DL ini tidak di kawal-selia dengan baik ia mungkin bakal menjadi lebih bahaya daripada kepala bom nuklear!
Ok, kenapa ML adalah teknik AI yang sangat hebat di waktu ini.
Sebagai contoh, katakan kita nak mengajar komputer untuk mengenali haiwan yang dikenali oleh manusia sebagai kucing. Mungkin agak mudah mengajar bayi yang berumur 3 tahun untuk mengenalinya, tetapi bolehkah anda bayangkan bagaimana sukar untuk melakukannya melalui teknik traditional AI? Secara traditionalnya, untuk memberi arahan atau mengajar komputer membuat perbandingan, ia boleh dilaksanakan dengan pendekatan rule-based melalui programming ataupun pengaturcaraan. Seperti contoh, dengan berpandukan pada pixel-pixel gambar seekor kucing seperti di bawah, anda perlu memprogram ribuan kod rule-based yang kompleks untuk membolehkan komputer mengenali kucing tersebut.

Bisa lakukannya? Ya mungkin boleh, berkat ketekunan dan kesabaran anda. Alhamdulillah selesai masalah.
Tunggu! Tunggu sebentar! Masih awal untuk bergumbira.
Cuba lihat gambar-gambar kucing di bawah. Bagaimana pula dengan kucing-kucing lain? ada ratus ribuan kucing di luar sana malahan berpuluh-puluh spesis kucing wujud di dunia ini. Bagaimana pula dengan keadaan kucing-kucing itu? ada yang sedang mengendap di tepi bakul, di urut tengkoknya, mulut mengiau luas, mendukung anaknya, dan sebagainya.
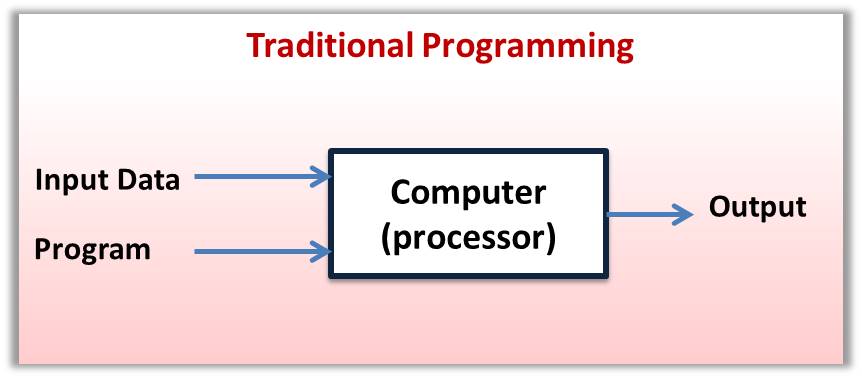
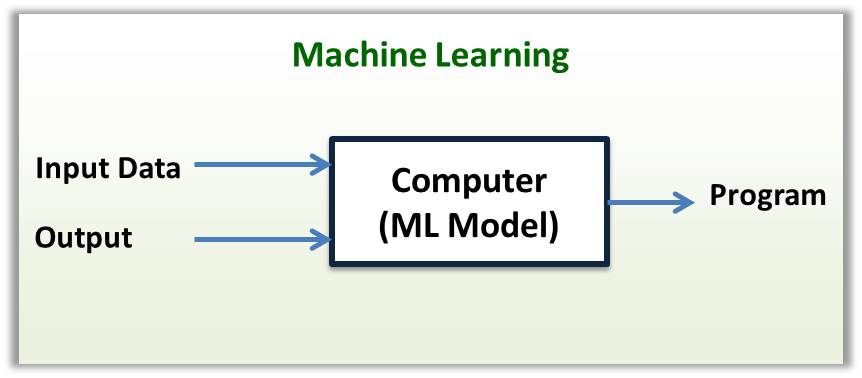
Dengan kata lain, bagaimana kita nak "generalize" kan kod rule-based ini supaya ia dapat mengenali kucing-kucing yang belum di "lihat" oleh komputer. Disinilah kekuatan ML mengatasi teknik traditional AI. Lihat gambarajah di bawah. Kaedah traditional programming, seperti yang dinyatakan di atas, ia memerlukan manusia membina program berdasarkan pada input data untuk menghasilkan model klasifikasi rule-based. Manakala, ML tidak memerlukan manusia untuk membina program tersebut secara eksplisit. Apa yang ML perlu ialah bantuan manusia melabelkan jawapan betul pada setiap input data, dan menyalurkankannya ke dalam komputer. Seterusnya, algoritma ML memproses data tersebut lalu membina model yang boleh mengklasifikasi data input yang belum di "lihat" sebagai kucing atau bukan kucing. Oleh kerana model klasifikasi tersebut boleh di bina secara automatik dan pantas oleh algoritma ML (dengan sedikit bantuan daripada manusia), kita boleh meningkatkan prestasi "generalization" model tersebut dengan menyumbat masuk pelbagai jenis gambar kucing kepada algoritma ML itu dengan skala yang besar (lebih banyak input data yang pelbagai, lebih tinggi prestasi generalization sebuah model).
Secara informalnya, ML boleh didefinasikan sebagai:-
Teknik AI yang membolehkan machine berupaya belajar tanpa perlu di program secara eksplisit
Secara formalnya pula ia didefinasikan sebagai:-
Suatu program komputer dikatakan belajar dari pengalaman E terhadap suatu kelas tugasan T dengan prestasinya di ukur dengan P. Prestasi pada ukuran P terhadap tugasan T meningkat melalui penambahan pengalaman E.
Definasi E, T & P dengan frasa lebih mudah:-
- T = Tugasan untuk mengenali kucing di dalam gambar
- E = Pengalaman melihat banyak gambar-gambar kucing
- P = Kebarangkalian program mengenal pasti kucing di dalam gambar
Untuk pengetahuan anda, ML terdiri dari beberapa kategori; iaitu Supervised Learning, Unsupervised Learning, Semi-Supervised Learning, Self-Supervised Learning, Reinforcement Learning, dan banyak lagi. Cuma kali ini, kita fokus pada teknik yang saya bincangkan di atas iaitu, Supervised Learning. Supervised Learning sangat mustajab digunakan untuk menyelesaikan masalah berkaitan Classification dan Regression (Saya akan jelaskan hal berkenaan regression kemudian).
Secara analoginya, Supervised Learning Classification adalah ibarat mengajar kanak-kanak mengenal kucing menggunakan kad flip.
- Cikgu: Ini apa?
- Murid: Itu ayam.
- Cikgu: Bukan, Ini kucing.
- Murid: Itu kucing.
Supervised Learning
Seperti yang dinyatakan sebelum ini, idea supervised learning classification adalah berdasarkan pada konsep mengajar kanak-kanak (murid) menggunakan kad flip.
- Cikgu = Supervisor
- Murid = Komputer
- Input Data = Gambar Kucing
- Input Label = Kapsyen pada Kad Flip
Gambarajah di bawah menunjukkan aliran proses supervised learning.
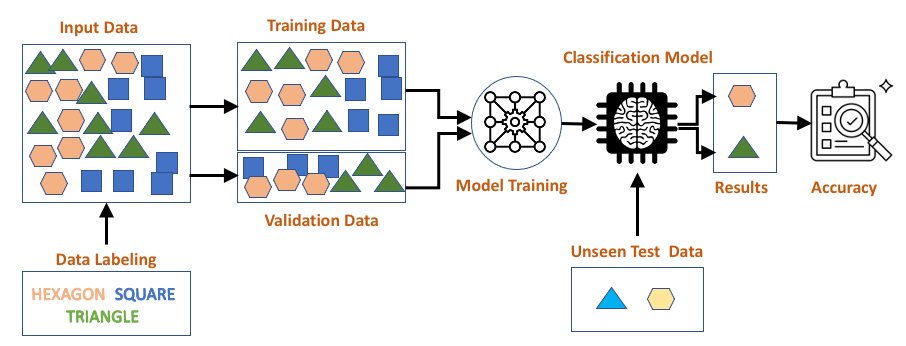
Langkah pertama untuk menjalankan proses Supervised Learning (SL) adalah mengumpul dan melabel atau menganotasi data. Kita bernasib baik sebab gambar-gambar kucing sudah pun ada banyak di google.com, mudah lah untuk kita mencuba ML dan DL nanti. Kita bukan sahaja boleh mendapatkan data daripada google.com dan Google Dataset Search, ada banyak benchmark data yang telah digunakan oleh penyelidik-penyelidik, ada di internet. Senarai dataset tersebut boleh di perolehi di sini, TowardsAI dan Wikipedia.
Ini adalah suatu kemudahan kan? banyak data sudah sedia ada untuk memberi galakan kepada anda menerokai teknologi ini (Anda masih perlu melakukan sedikit proses penyesuaian data, ianya agak mudah dilakukan).
Data Preprocessing
Namun, jika anda ingin mengunakan ML untuk menyelesaikan permasalahan sebenar di luar sana, pengumpulan dan penyediaan datanya tidak lah semudah itu. Anda perlu melalui proses Data Pre-processing terlebih dahulu.
- Data Cleaning
- Missing Data
- Contohnya, jika ada atribut rekod di dalam data tersebut hilang, padamkan rekod itu.
- Ataupun simpan rekod itu, tetapi nilai pada atribut yang hilang digantikan dengan nilai average atribut. (Rekod dan atribut adalah satu jaluran informasi dalam data)
- Jika data tersebut adalah imej, kita boleh membuang data yang tidak sesuai secara visual sebelum atau secara automatik selepas training. Fastai adalah framework deep learning untuk Pytorch, mempunyai fitur untuk menyenaraikan data yang tidak baik secara automatik selepas menjalankan proses training.
- Noisy Data
- Noisy data adalah data yang dikatakan "meaningless", "takda maknanya". Macam bunyi noise + muzik, bunyi noise itu kalau tak ada lagi sedap bunyi muziknya. Ia boleh diuruskan melalui teknik seperti Binning, Regression, dan Clustering (melandaikan data, mengurangkan zig-zag). Ada juga yang mencadangkan dengan menambahkan lebih banyak data yang berkualiti untuk mengurangkan kesan noisy data. Kaedah-kaedah lain adalah seperti teknik dimension reduction (seperti algoritma PCA), teknik Regularization, dan Cross Validation. Ironinya noise (random noise) merupakan rakan baik untuk algoritma DL. Contohnya, random noise sengaja di suntik masuk ke dalam data (teknik Data Augmentation) sebelum ia disalurkan ke dalam algoritma DL regression untuk meningkatkan tahap generalization modelnya (salah satu teknik Regularization dalam DL). Manakala algoritma DL Generative Adversarial Network (GAN) pula menggunakan random noise sebagai dasar untuk mencipta "fake face images", muka manusia tiruan.
- Outlier Data
- Outlier data adalah data yang berada jauh daripada kelompok data lain dari segi kesamaan dan keberkaitannya. Kebiasaannya outlier data perlu di buang (mungkin disebabkan human error), namun ada ketikanya seperti untuk anomaly detection (mengesan sesuatu di luar kebiasaan seperti aktiviti hacker, network intrusion, dan penipuan dalam talian), dalam konteks ini outlier data adalah penting.
- Missing Data
- Data Transformation
- Normalization
- Normalization menyeragamkan skala nilai pada setiap atribut di rekod. Kebanyakkan algoritma memerlukan semua atribut tersebut diseragamkan di antara julat yang sama. Contohnya, jika julat atribut Harga Rumah adalah 50,000 dan 500,000 dan julat atribut Jumlah Bilik adalah 2 dan 8 (Contoh atribut data berkenaan hartanah), ia perlu diseragamkan di dalam julat yang sama untuk membolehkan algoritma berfungsi dengan baik. Algoritma seperti NN sebagai contoh, memerlukan input data yang diseragamkan kepada nilai di antara 0 dan 1.
- Discretization
- Menukarkan julat nombor tertentu kepada perkataan. Contohnya, nilai antara 1 dan 17 -> Kanak-Kanak, 18 dan 39 -> Dewasa, 40 dan 59 -> Pertengahan, 60 dan ke atas -> Wargamas.
- Encoding Categorical Value
- mengekod nilai atribut dari perkataan kepada nombor binary. Contoh, Kucing -> 100, Ayam -> 010, dan Monyet -> 001. Ini perlu dilakukan terutamanya untuk algoritma seperti NN yang hanya boleh berfungsi dengan nilai input, outputnya di dalam bentuk nombor sahaja.
- Data Labeling
- Data labeling atau annotation yang diperkatakan di atas juga adalah teknik data preprocessing yang mesti dilakukan sebelum proses supervised learning. Jika data tersebut adalah imej, anda perlu menanda pada imej tersebut, objek yang ingin diklasifikasikan. Bayangkan jika anda perlu menganotasikan pada 50 ribu keping gambar yang mana setiap keping gambar itu ada 1000 orang!
- Normalization
- Data Dimension Reduction
- Feature Extraction
- Memilih atribut-atribut yang relevan dan menggabungkannya menjadi satu atribut yang baharu.
- Feature Selection
- Memilih atribut yang relevan dan membuang atribut yang tidak relevan.
- Kedua-dua teknik ini bukan sahaja mengurangkan dimensi data, ia juga dikatakan akan menjadikan data tersebut lebih bermakna dan mudah di latih oleh algoritma ML. Ada banyak algoritma yang boleh digunakan untuk data dimension reduction ini, tapi saya tak membincangkannya di sini kerana algoritma DL yang kita akan terokai nanti dikatakan mampu beraksi dengan baik tanpa perlu melalui proses ini dilakukan secara manual.
- Feature Extraction
Model Training
Apakah yang dimaksudkan dengan model training?
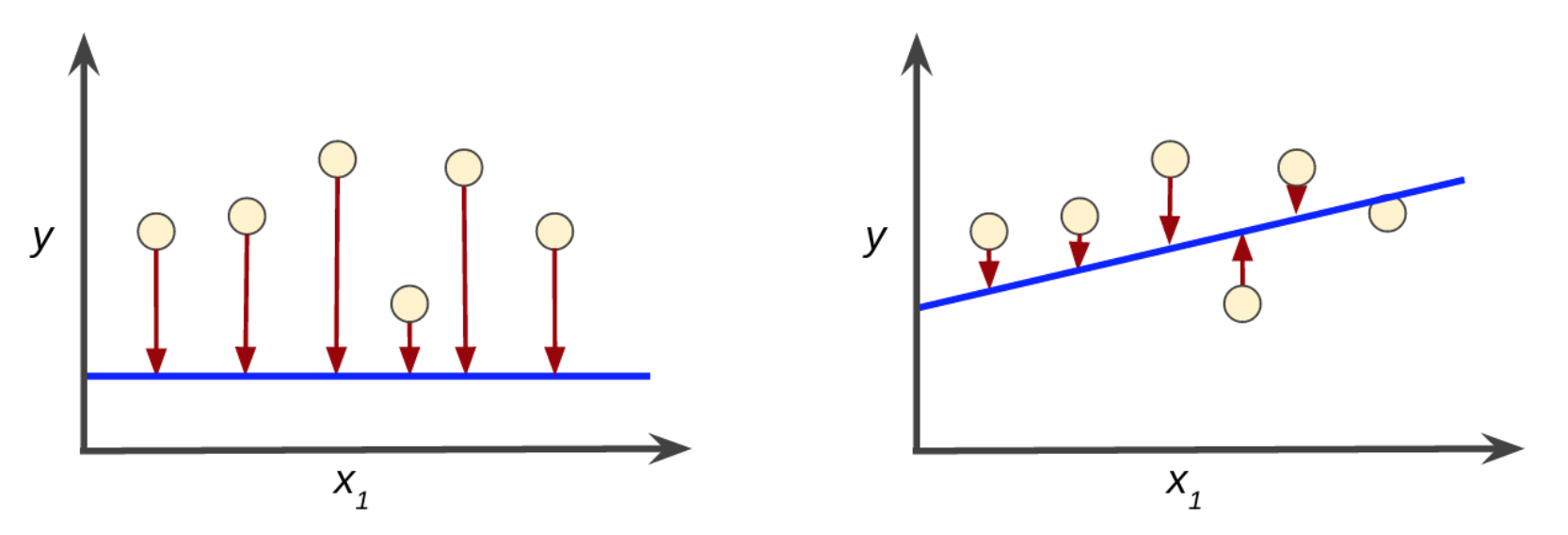
Graf di bawah menunjukkan hubungan antara dua pemboleh ubah X, Y dan garisan persamaan linear di garis melintasi data yang diplotkan. Proses ini dikenali sebagai Simple Linear Regression Model, contoh ini adalah yang paling mudah kita gunakan kerana ia hanya melibatkan dua pemboleh ubah (atribut 2 dimensi). Bulatan kuning adalah training data manakala garisan biru adalah model yang digariskan oleh algoritma ML melalui proses training. Anak panah berwarna merah merupakan jarak atau error antara training data dan nilai pada garisan model f(X)->Y. Melalui proses training, algoritma ML perlu membina garisan model f(X)->Y yang minima jumlah errornya berbanding dengan point training data (seperti yang ditunjukkan pada graf sebelah kanan).
Rumus di bawah adalah persamaan linear yang merujuk pada garisan yang berwarna biru.
Nilai pemboleh ubah a menentukan kecerunan, manakala pemboleh ubah b menentukan ketinggian garisan tersebut pada paksi Y. Graf di sebelah kiri merupakan garisan permulaan model linear regression itu pada ketika a=0 dan b=1. Pada ketika ini nilai prediksi model f(X) -> Y pada setiap titik x training data adalah 1. Jumlah error ketika ini boleh di hitung dengan menggunakan rumus Mean Square Error (MSE).
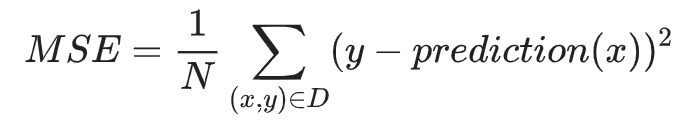
Merujuk pada rumus MSE di atas:
- x adalah independant variable ataupun input fitur yang digunakan oleh model untuk melakukan prediksi nilai dependant variable ataupun target value, y.
- prediction(x) adalah nilai prediksi y di input x berdasarkan model linear regression ketika di suatu nilai a dan b.
-
D adalah training data yang telah dilabelkan. x ialah input fitur manakala y ialah output labelnya. Contoh graf di atas menunjukkan ada 6 data point dengan input fitur dan label seperti berikut:-
(x1,y1), (x2,y2), (x3,y3), (x4,y4), (x5,y5), (x6,y6)
- N adalah jumlah training data (contoh di atas, N = 6).
Untuk menghitung MSE, pada setiap data point, dapatkan error antara nilai y label dan y prediksi, kemudian kuasa duakannya. Lakukan ini pada setiap data point, kemudian jumlahkan kesemuanya. Akhir sekali, bahagikan hasil jumlah tersebut dengan jumlah training data, N (merujuk pada contoh di atas, N = 6).
Proses yang merujuk pada graf di kiri itu adalah dikatakan sebagai "initial iteration per 1 epoch".
Apa maksudnya?
Initial di sini bermaksud nilai permulaan parameter a dan b bagi mengariskan kedudukan awal garisan model linear tersebut. Nilai a dan b itu boleh ditentukan supaya bermula dengan nilai kosong ataupun nilai random (Untuk architecture NN yang kompleks kita mungkin perlu menggunakan kaedah lain yang lebih spesifik).
Iteration adalah frekuensi algoritma ML itu disuapi sebahagian daripada training data. Epoch pula adalah frequency kesemua training data itu selesai di proses oleh algoritma ML tersebut.
Boleh faham tak maksudnya? Ok, saya jelaskan dengan lebih terperinci.
Dalam keadaan sebenar, kesemua training data itu tidak di suap masuk ke dalam algoritma secara serentak. Ia di suap mengikut kumpulan atau batch. Contoh, jika jumlah training data adalah 2000 (1 epoch = 2000 data di proses). Jika anda setkan saiz batch = 100, maka setiap 1 epoch = 20 iteration (20 x 100 = 2000). Jika anda setkan training proses sebanyak 250 epoch maka total iterationnya adalah 20 x 250 = 5000. Ingat, pengiraan MSE berlaku pada setiap iteration. Macam mana, Ok?
Untuk contoh di atas, oleh kerana training datanya cuma ada 6 sahaja, maka setiap 1 epoch ada 1 iteration sahaja (kita setkan saiz batch = jumlah training data, iaitu 6). Oleh itu pada setiap 1 iteration, nilai MSE di hitung berdasarkan pada kedudukan terkini garisan linear model. Kedudukan garisan linear model akan berubah pada setiap iteration. Dengan harapan nilai MSEnya semakin kecil.
Apa yang akan berlaku jika anda setkan training proses sebanyak 250 epoch? Cukup ker?
Maksudnya, algoritma ML tersebut ada masa sebanyak 250 iteration untuk mengariskan linear regression modelnya (melalui kombinasi nilai parameter a dan b) supaya MSE mencapai nilai seminima yang mungkin. Secara teorinya, lagi lama iteration maka semakin tinggilah peluangnya mencapai nilai MSE yang paling minima. Namun ini bergantung kepada keupayaan algoritma ML menentukan nilai parameter a dan b yang optimum dalam jangkamasa yang singkat. Bayangkan jika algoritma ini menggunakan teknik random atau brute-force bagi menentukan nilai parameter a dan b itu. Iteration sebanyak 250 mungkin tidak mencukupi kan?
Algoritma Deep Learning menggunakan teknik optimization yang di panggil "Gradient Decent" untuk mencapai nilai MSE yang minima, jauh lebih pantas berbanding teknik secara random.
Bayangkan jikalau bukan 2, tapi ada beribu parameter yang perlu ditentukan? Dengan Gradient Decent, ia mungkin memakan masa dalam beberapa puluh minit, tapi jika secara random, anda mungkin perlu menunggunya selama beribu-ribu tahun!
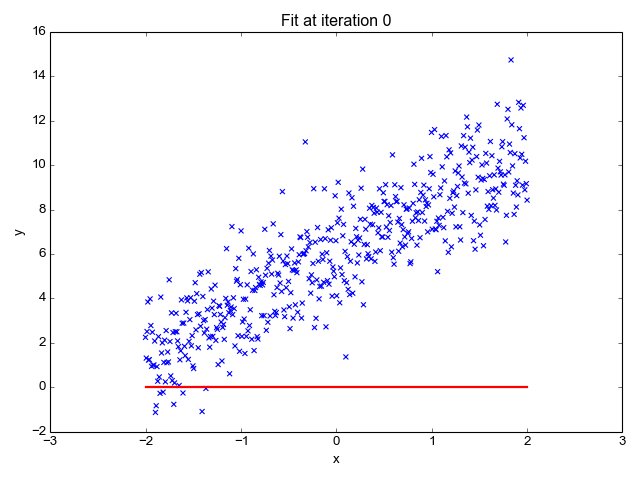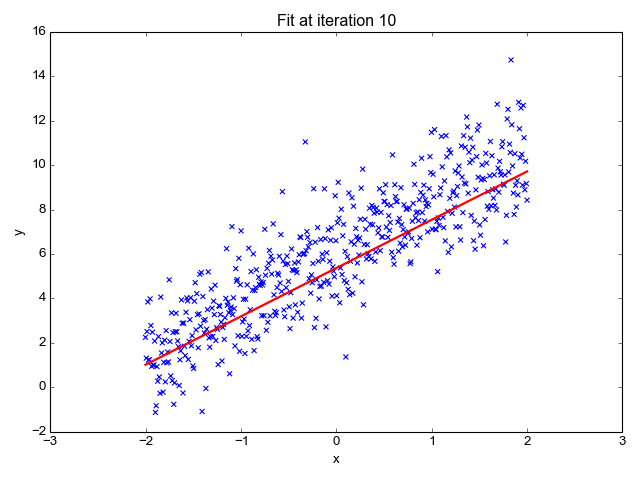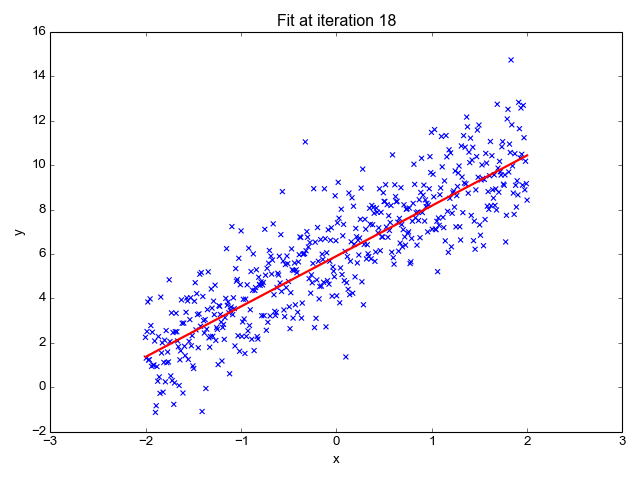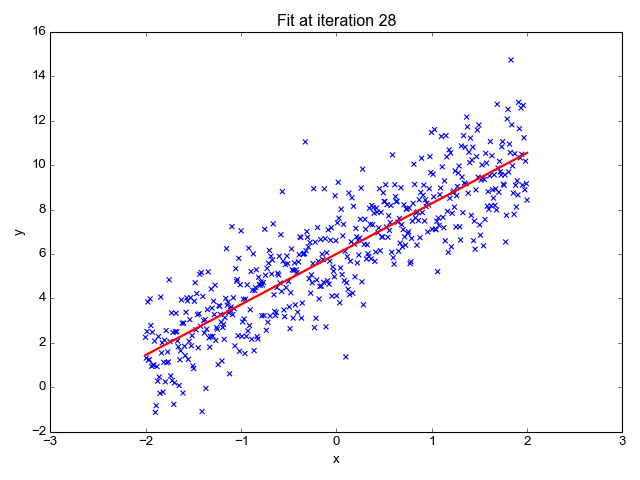
Gambarajah di atas adalah contoh linear regression model yang mencapai tahap optimum pada iteration yang ke-28 berdasarkan pada jumlah training datanya.
Model Validation
Saya harap anda sudah memperolehi kefahaman asas berkenaan model training, tapi mungkin ada yang tertanya-tanya, apa kaitannya validation data dengan model training? Saya pun langsung tak melibatkan validation data di dalam penerangan berkenaan model training tadi.
Jika anda merujuk kembali pada gambarajah aliran proses supervised learning. Ada tiga jenis data yang perlu disediakan selepas proses labeling data,
- Training Data
- Validation Data
- Testing Data
Seperti yang telah saya jelaskan sebelum ini, training data diperlukan untuk membina model classification ataupun regression. Manakala, testing data pula adalah "unseen data" yang telah diasingkan bagi tujuan mengukur prestasi model tersebut.
Sebenarnya fungsi validation data juga adalah sama dengan test data iaitu mengukur prestasi model yang telah di bina. Cuma bezanya adalah, validation data digunakan untuk mengukur prestasi model ketika di dalam proses model training.
Ada beberapa teknik validation iaitu,
- Holdout Method
- Sebahagian dari training data diasingkan kepada validation data (mungkin dalam nisbah 90% training dan 10% validation data, atau 80% dan 20%).
-
K-Fold Cross Validation
-
Teknik ini sesuai digunakan untuk membolehkan anda mengoptimumkan penggunaan training data. Terutamanya, jika anda tidak mempunyai training data yang cukup banyak.
-
Gambarajah di bawah menunjukkan gambaran proses 10-fold cross validation (K=10).
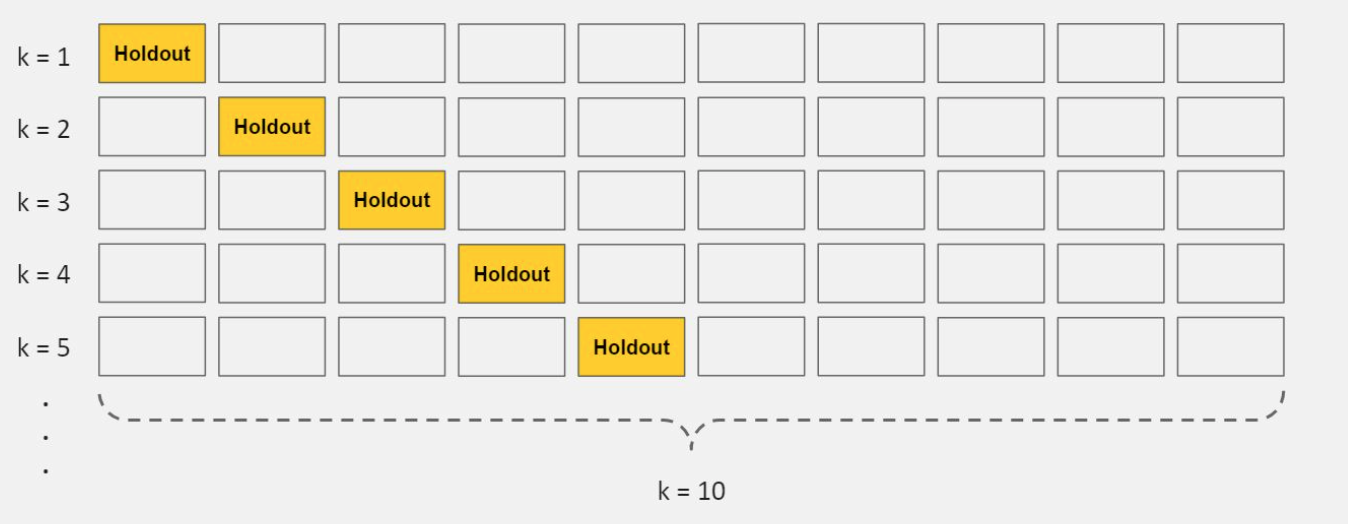
-
Berikut adalah langkah-langkah proses 10-fold cross-validation,
- Asingkan data kepada 10 bahagian yang sama atau "folds".
- Train model anda menggunakan 9 folds data yang pertama.
- Buat penilaian prestasi model itu menggunakan baki ataupun "hold-out" data fold yang ke-10 tadi.
- Ulangi langkah (2) dan (3) sebanyak 10 kali, di mana setiap ulangan menggunakan hold-out data fold yang berbeza.
- Hitungkan purata prestasi model daripada kesemua 10 hold-out data folds tersebut.
-
-
Stratified K-Fold Cross Validation
- Teknik ini masih menggunakan langkah yang sama seperti di atas. Stratified adalah nama teknik sampling data yang digunakan untuk memilih data ketika mengasingkan data kepada training dan validation. Teknik sampling data yang digunakan oleh dua teknik validation sebelum ini adalah random data sampling. Teknik stratified data sampling digunakan jika data yang anda perolehi itu tidak seimbang. Contohnya, training data untuk harga rumah yang mahal lebih banyak daripada harga rumah yang murah, ataupun training data gambar kucing ada lebih banyak daripada gambar anjing dan monyet.
K-fold cross validation dikatakan,
Secara signifikan mengurangkan "bias" kerana menggunakan sebahagian besar training data yang ada. Ia juga secara signifikannya mengurangi "variance" kerana sebahagian besar data juga digunakan sebagai validation data.
Bias? Variance? mungkin ada yang tertanya-tanya akan maksudnya.
Istilah Bias & Variance ini berkait rapat dengan keperluan untuk mengukur prestasi model ketika dalam proses model training yang kemudiannya dijadikan sebagai rujukan bagi melakukan proses Model Tuning.
Model Tuning & Testing
Berkenaan dengan model tuning, berikut adalah beberapa istilah penting yang perlu anda fahami.
- Bias & Variance
- Underfitting & Overfitting
- Generalization
- Hyperparameter Tuning, Regularization & Optimization .
Wow! Banyaknya nak kena hafal.
Jangan risau, tak banyak mana pun sebenarnya, sebab mereka ni semua saling berkaitan. Yang penting kita jelas dengan maksudnya supaya tak terkeliru dan dikelirukan. Ini kerana, di luar sana ada ramai yang mengamalkan teknik ini,
"If you can't convince them, confused them"
Untuk memudahkan anda faham, gambarajah di bawah menggarap maksud istilah Bias & Variance, Underfitting & Overfitting, dan Generalization sekali gus.
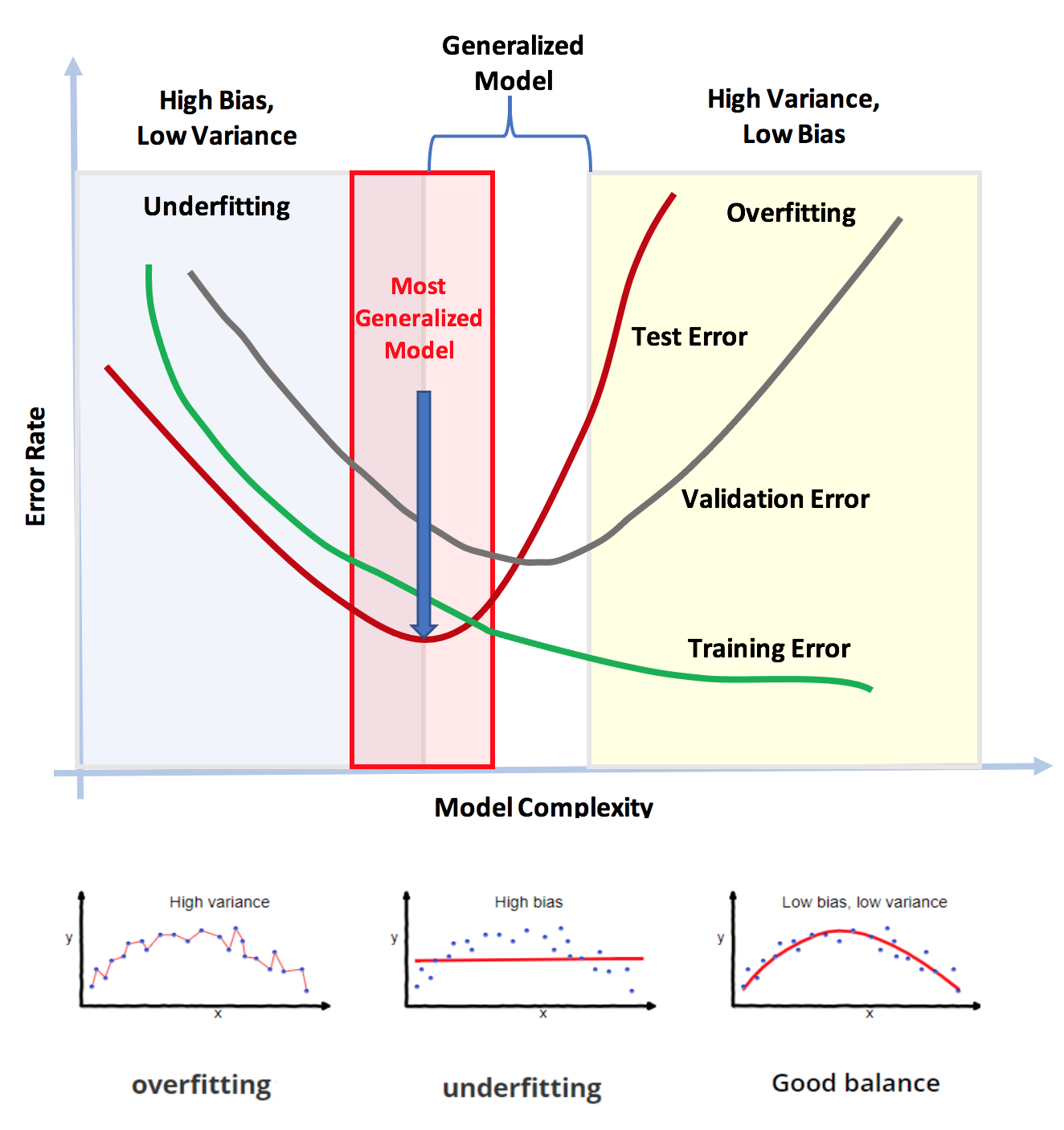
Gambarajah di atas menunjukkan error rate menurun apabila kompleksiti model meningkat (Peningkatan kompleksiti model adalah berkadar terus dengan frequency iteration atau epoch). Iaitu, lagi lama proses model training berjalan maka lagi kompleks lah model yang terhasil. Secara teorinya, semakin lama model di train maka semakin kecil lah errornya (menghampiri kosong), namun ini tidak semestinya baik.
Kenapa pulak? Error model dah zero, mesti lah terbaik kan? Tidak!
Cuba anda lihat tiga graf kecil di bawah gambarajah itu.
Overfitting = High Variance, Underfitting = High Bias, Good Balance = Low Bias, Low Variance.
Apabila training iteration tak mencukupi, model yang dihasilkan adalah simple iaitu garisan linear yang tidak mampu untuk "fit" pada trend data yang non-linear. Sebaliknya, jika terlalu lama di train, model yang terlampau "fit" pada trend data itu akan terhasil. Cuba anda perhatikan, apabila semua garisan model itu "overfit" kerana ia melalui kesemua titik training data. Oleh itu, errornya memanglah menjadi kosong kan? (masih ingat pengiraan MSE?). Namun, prestasi model ini hanya baik pada data yang pernah dilihatnya sahaja dan bukan pada "unseen" data.
Inilah yang dikatakan sebagai "Bias & Variance Tradeoff". Iaitu, mencari Good Balance, Sweet Spot ataupun Generalized Model, mampu memberi prestasi yang baik apabila modelnya di nilai dengan data baharu. Oleh itu, dengan berpandukan pada titik error rate terendah validation dan test error, maka anda boleh menentukan nilai iteration atau epoch yang paling optimum.
Ok. Sekarang baru lah saya boleh bercakap tentang Model Tuning & Testing.
Jika sudah selesai melakukan model training dengan tetapan nilai epoch yang optimum, maka anda telah bersedia untuk mengukur prestasi model anda dengan unseen test data (anda boleh melakukannya pada beberapa model terpilih). Jika anda bernasib baik, nilai ketepatannya mungkin lebih baik daripada validation error, atau mungkin sebaliknya.
Jangan cepat berpuas hati! Masih ada ruang untuk "tune up" prestasi model anda melalui Hyperparameter Tuning, Regularization & Optimization (dalam konteks deep learning).
Hyperparameter adalah parameter pada algoritma yang boleh di ubah-ubah settingnya untuk mencari kombinasi yang optimum. Ibarat macam amplifier audio, kita pusing-pusing tombol-tombolnya untuk mencari bunyi yang paling enak. Hyperparameter juga dikatakan sebagai "non-learnable" parameter manakala "learnable" parameter hanyalah pada model parameter. Contoh model parameter ialah nilai parameter a dan b untuk simple linear regression model y = Ax + b. Ini adalah kerana nilai a dan b itu ditentukan (learned) oleh algoritma dan training data ketika proses model training. Regularization adalah teknik atau setting yang boleh meningkatkan tahap generalization model. Optimization adalah pemilihan jenis algoritma Gradient Decent (GD) dan setting parameternya.
Senarai hyperparameter pada DL algoritma adalah seperti berikut:-
- Jumlah NN Hidden Layer (NN Parameter)
- Jumlah Nod di setiap NN layer (NN Parameter)
- Pemilihan Activation Function di setiap NN layer seperti RELU, Tanh, Sigmoid, etc (NN parameter)
- Batch Normalization (Regularization)
- Setting Learning Rate (GD Optimization)
- Early stopping (Regularization)
- L2 & L1 norm (Regularizatioan)
- Tambah training data (Regularization)
- NN node Drop-out (Regularization)
- Data Augmentation (Regularization)
- Mini-batch size (GD Optimization)
- Momentum (GD Optimization)
- RMSprop (GD Optimization)
- ADAM (GD Optimization)
- Learning Rate Decay (GD Optimization)
Banyak kan? Sebenarnya ada banyak lagi! 눈_눈
Ini kalau nak diceritakan teori dan matematik merujuk pada semua di atas ni, Mau pecah la kepala otak saya. Tapi jangan risau, kita guna jer kod implementasinya di library Tensorflow/Keras dan Pytorch. Tapi kalau nak tune semua ni satu persatu, penat laa! lecehnya!. Ya betul memang leceh, tapi nasib baik ada library automation untuk tujuan hyperparameter tuning ni. Antara yang popular untuk Tensorflow/Keras dan Pytorch ialah,
- AutoML
- Keras Tuner
- T-PoT
- Hyperas
- Talos
- Hypersearch
- Optuna
- Determined
- Ray Tune
Banyak kan? Sebenarnya ada banyak lagi! 눈_눈
Saya rasa cukuplah sampai di sini. Di artikel yang seterusnya InsyaAllah saya akan cuba menulis yang lebih spesifik pada teori berkaitan deep learning dan implementasinya pula.
Dengan ini, harapan saya semoga artikel ini dapat memberi manafaat kepada pembaca yang berminat meneroka di dalam teknologi ini. Jika anda ingin mengetahui dengan lebih lanjut, memanglah ada berlambak-lambak bahan-bahan pembelajaran berkenaan DL di google.com dan youtube. Tapi hampir kesemuanya adalah dalam bahasa inggeris lah, dan adalah juga sedikit dalam bahasa Indonesia. Mungkin tak menjadi masalah sangat pada rata-rata orang kita, kerana ramai orang Malaysia mahir berbahasa inggeris, pokoknya adalah minat dan kesabaran yang mendalam.
Assalamualaikum!