Pengenalan Kepada Perceptron
Perbincangan berkenaan konsep asas deep learning
Assalamualaikum. Selamat berjumpa kembali.
Seperti yang saya maklumkan pada artikel yang lepas, saya telah berjanji untuk cuba memberikan sedikit penerangan asas berkenaan teori DL ini. Kalau nak diikutkan, jika kita menggunakan library Tensorflow atau Pytorch nanti, kesemua yang kita bincang ini akan diabstrakkan implementasinya.
Dengan kata lain, "Tak payah tau pun, pakai jer".
Tapi saya rasa anda perlu tahu juga konsep asasnya terlebih dahulu, sebab ini akan membantu anda untuk majukan ke tahap penggunaan DL yang lebih kompleks. Lagipun, tak kanlah nak pakai jer library Tensorflow atau Pytorch membuta tuli kan?
Perceptron
Perceptron adalah salah satu architecture ANN yang paling asas, dicipta pada tahun 1957 oleh Frank Rosenblatt. Ia berdasarkan pada konsep neuron (lihat gambar di bawah) yang disebut Treshold Logic Unit (TLU), ataupun Logic Treshold Unit (LTU). Nilai input dan outputnya adalah nombor (bukan nilai on/off binari), dan setiap sambungan di antara input nod dan output nod itu diberikan nilai pemberat atau weight. Secara analoginya, lagi besar weight maka lagi tebal lah wayar sambungannya (Lagi besar pengaruhnya).
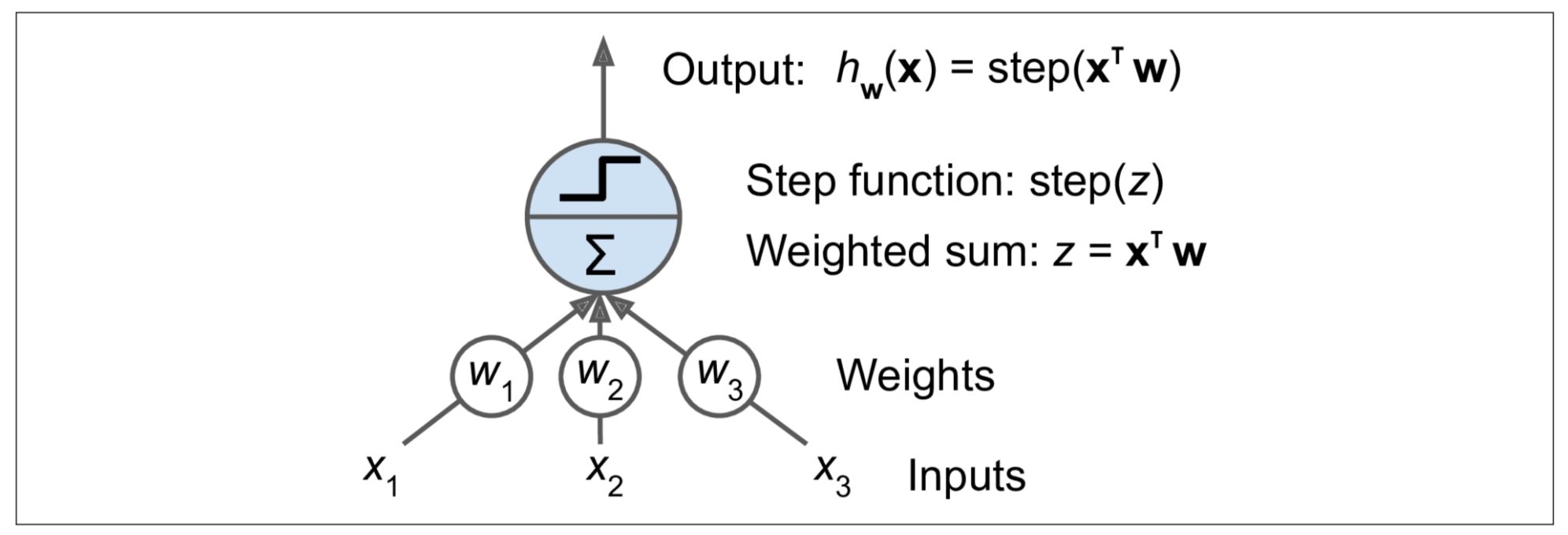
TLU menghitung jumlah weight berserta dengan inputnya seperti yang ditunjukkan oleh rumus di bawah,
kemudian hasil z itu diaplikasikan kepada fungsi step(z) untuk menghasilkan nilai output yang baharu,
Menyingkap kembali pada artikel yang sebelum ini, ia masih menggunakan rumus yang sama iaitu y = ax + b tanpa pembolehubah b. Merujuk pada ini, ada sedikit perbezaan iaitu nilai output adalah hasil dari 3 input fitur x dengan nilai pengaruh weight w (dahulunya a) pada setiap fitur tersebut. Perbezaan yang paling utama adalah peranan Step Function sebagai "Activation Function". Idea activation function ini penting untuk membolehkan kita membina model yang non-linear (perceptron adalah algoritma linear untuk klasifikasi binari kerana nilai aktivasinya adalah 1 atau 0). Kenapa kita perlukan model non-linear? Cuba ingat balik fakta dari artikel yang lepas, garisan linear hanya mampu menghasilkan suatu model yang underfit atau high bias. Ini bukan suatu model yang kita inginkan untuk menyelesaikan masalah yang kompleks.
Mungkin ada yang tertanya-tanya kenapa ada huruf superscript T di atas huruf x itu?
Ini kerana ia melibatkan pengiraan menggunakan Matrix Multiplication. Janganlah rasa takut bila dengar terma matrix ini. Anda hanya perlu tahu asas berkenaan ilmu matematik matrix yang di pelajari di sekolah menengah. Lagipun semua pengiraan ini nanti akan dilakukan oleh library Tensorflow atau Pytorch.
Ok. Huruf T adalah merujuk kepada proses matrix yang di panggil Transpose. Ia diperlukan untuk membetulkan bentuk dimensi matrix x bagi membolehkan ia multiply dengan matrix w. Contoh, jika bentuk dimensi matrix x dan w adalah (3,1), operasi matrix dimensi x(3,1) x w(3,1) itu perlu ditukarkan ke bentuk x(1,3) x w(3,1) terlebih dahulu dengan melakukan proses transpose pada matrix x.
Jika anda sudah lupa berkenaan operasi asas matrix, bolehlah rujuk kembali pada buku SPM anda. InsyaAllah, sayang anda pada cikgu matematik akan bertambah.
Ok. Bagaimana pula dengan Step Function?
Cuba lihat notasi matematik di bawah. Ia merujuk kepada dua jenis fungsi Step bernama Heaviside dan Sign. Dulu saya cukup fobia bila melihat notasi matematik dengan simbol macam cacing ni. Tapi sebenarnya jika anda cuba amati notasi tersebut ia sebenarnya adalah merupakan satu "bahasa" simbolik. Jika anda hafal maksud simbol-simbolnya maka mudahlah memahami maksudnya.
Fungsi heaviside akan mengeluarkan nilai 0 jika nilai z adalah lebih kecil daripada 0. Sebaliknya, ia mengeluarkan nilai 1 jika nilai z adalah sama atau lebih besar daripada 0.
Manakala fungsi Sign pula akan mengeluarkan nilai -1 jika nilai z adalah lebih kecil daripada 0. Ia juga mengeluarkan nilai 0 jika nilai z adalah 0, dan mengeluarkan nilai +1 jika nilai z adalah lebih besar daripada 0.
Untuk memberi gambaran jelas pada yang "visual learner", cuba lakarkan graf pada paksi z -> X dan sgn(z) -> Y. Saya serahkan pada anda untuk melakarkannya.
Architecture TLU tunggal ini boleh digunakan untuk klasifikasi binari yang mudah seperti Hujan (1) atau Tidak (0). Ia menghitung kombinasi linear dari 3 input x (dengan nilai weight masing-masing), dan jika hasil z melebihi nilai treshold (z >= 0) seperti yang ditetapkan oleh contohnya fungsi heaviside, ia akan menghasilkan prediksi kelas positif (1). Jika sebaliknya, ia menghasilkan prediksi kelas negatif (0). Melatih TLU dalam kes ini bermaksud mencari nilai yang optimum untuk weight w1, w2, dan w3 itu.
Perceptron hanya terdiri daripada satu lapisan TLU, dengan setiap TLU disambungkan ke semua input. Apabila semua neuron dalam lapisan disambungkan ke setiap neuron pada lapisan sebelumnya (iaitu, neuron inputnya), lapisan tersebut disebut fully connected layer, atau dense layer. Input fitur yang memasuki lapisan TLU itu dianggap sebagai lapisan input neuron ( tiada pemprosesan berlaku di neuron ini). Kebiasaannya, input bias di tambah (seperti nilai b pada y=ax+b untuk linear regression model bergerak ke atas dan bawah paksi y, tetapi untuk DL ada tujuan tambahan) menggunakan neuron khas yang disebut neuron bias (Ia ditetapkan dengan nilai 1). Gambarajah di bawah menunjukkan perceptron dengan dua input, satu input bias dan tiga output.
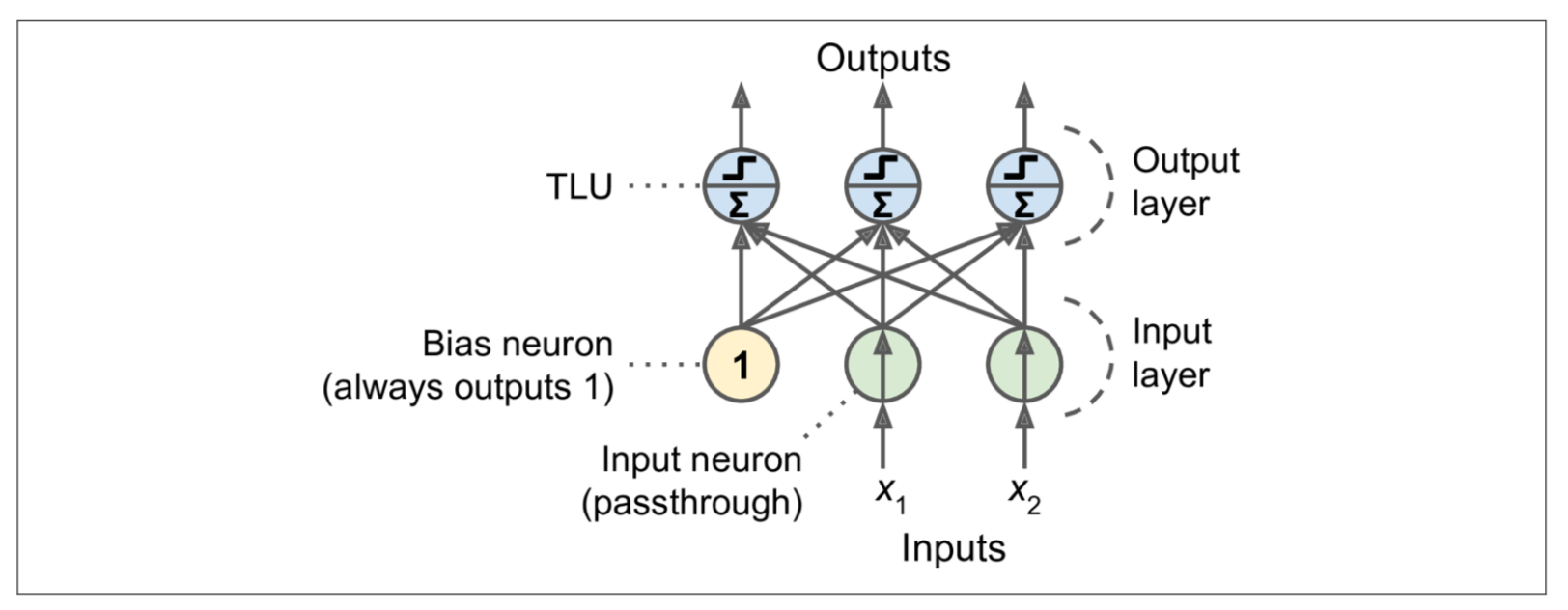
Apa tujuan lain bias? kenapa nilainya disetkan dengan nilai 1?
Anda tahu bahawa nilai output untuk 1 neuron TLU dan 1 input ditentukan oleh input, weight dan activation function step heaviside seperti berikut,
y = f (x₀ × w₀)
Sekiranya input adalah x₀ = 0 maka y = f (0) = 1.
Ini menyebabkan neutron tersebut sentiasa menghasilkan output yang sama (1) walaupun nilai weight w₀ berubah-ubah. Ia menyebabkan neuron itu berhenti belajar (neuron tidak aktif). Nilai bias=1 (y = f (x₀ × w₀ + 1) ), memastikan supaya neuron itu masih aktif walaupun nilai inputnya 0 (bias mengubah takat treshold atau trigger value activation function untuk neuron tersebut).
Semestinya nilai bias=1 sahaja ker? Tidak!
Bias juga adalah learnable parameter seperti weight parameter. Nilai 1 itu adalah tetapan permulaannya sahaja. Merujuk kepada gambarajah perceptron di atas, rumus untuk menghitung output lapisan fully connected adalah seperti berikut.
Penerangan rumus:
- X mewakili matrix fitur input. Ia mempunyai satu row pada setiap rekod (juga di panggil sample atau instance) dan satu column pada setiap fitur (Awak bayangkan row dan column pada MS Excel). Merujuk pada gambarajah perceptron di atas, jika kita ada 1000 instance, maka saiz matrik X adalah (1000, 2).
- Matrix weight W mengandungi semua sambungan weight antara neuron input dan neuron output kecuali neuron bias. Ia mempunyai satu row bagi setiap neuron input dan satu column bagi setiap neuron TLU lapisan output. Merujuk pada gambarajah di atas (kita ada 2 neuron input dan 3 neuron output), maka saiz matrix W adalah (2,3).
- Vektor bias b mengandungi semua hubungan weight antara neuron bias dan neuron ouput. Iaitu ia mempunyai satu neuron bias bagi setiap neuron output TLU.
- Fungsi φ ialah fungsi activation. TLU menggunakan fungsi step sebagai fungsi activationnya (kita akan membincangkan fungsi activation lain pada artikel yang seterusnya).
Bagaimanakah proses training dilakukan oleh perceptron?
Konsepnya adalah sama dengan yang telah saya jelaskan pada artikel yang sebelum ini. Seperti contoh, setiap data instance atau sample itu dilabelkan dengan nilai target seperti contoh, Hujan(1) & Tidak(0),
Dalam proses training, hanya satu instance atau sample di sumbat masuk pada satu masa. Namun hanya input fitur x (tanpa nilai target) sahaja yang akan disambungkan pada neuron TLU. Manakala nilai target daripada instance itu akan digunakan untuk mengukur error (nilai ramalan - target label). Output TLU neuron menghasilkan (melalui fungsi step) nilai ramalan sama ada 1 atau 0 berdasarkan pada variasi nilai weight w. Pada setiap kali (melalui proses iteration) neuron output itu menghasilkan ramalan yang salah, ia akan mempertingkatkan nilai weight w antara neuron input dan TLU tersebut sehingga ramalannya menjadi betul. Iaitu pada setiap iteration, nilai weight w akan diupdatekan (lihat rumus di bawah. i adalah row, j adalah column) mengikut error sama ada ke arah 1 atau 0.
Tetapi macam mana nak dikaitkan nilai
dengan nilai error (ramalan - target label)?
Secara logiknya adalah dengan mengurangkan weight w jika neuron diaktifkan (1) walaupun ia sepatutnya tidak (0) diaktifkan, (ramalan: y = 1 dan target: t = 0).
Sebaliknya dengan meningkatkan weight w jika neuron tidak (0) diaktifkan walaupun seharusnya diaktifkan (1), (ramalan: y = 0 dan target: t = 1).
Oleh itu kita boleh gantikan dengan
Iaitu, jika sepatutnya aktif (1):
Δw(i,j)=-(0–1)=1 (tingkatkan weight w)
dan jika tidak sepatutnya aktif (0):
Δw(i,j)=-(1–0)=-1 (kurangkan weight w)
Kita masih lagi ada satu masalah, bagaimana kalau nilai input X adalah negative? Ini akan menyebabkan nilai output neuron menjadi terbalik
output TLU = h(-XW + b)
Keadaan ini akan menyebabkan neuron tidak diaktifkan walaupun sepatutnya ia perlu diaktifkan (t=1, y=0). Begitu juga sebaliknya (t=0, y=1). Oleh itu rumus ini diperbaiki menjadi seperti berikut,
di mana:
- w(i,j) adalah weight yang menghubungkan input i ke output neuron j
- y(j) adalah output ramalan
- t(j) adalah nilai target label
- x(i) adalah input fitur
- µ adalah kadar kelajuan pembelajaran (learning rate).
Apa keperluannya untuk set nilai learning rate? Tujuannya adalah untuk memperlahankan sedikit kadar kelajuan neuron itu belajar.
Aiik! kenapa nak diperlahankan pulak? Bukan lagi cepat lagi bagus ker? Tidak!
Macam ni lah. Ia ibarat macam anda nak memasukkan benang ke dalam lubang di jarum. Cucuk masuk cepat-cepat bagus ke? Masih ingat di artikel sebelum ni? Learning rate juga adalah salah satu hyperparameter tuning yang anda perlu lakukan.
Di bawah adalah contoh mudah penggunaan perceptron. Anda perlulah mempunyai ilmu asas dalam programming untuk memahami kod python itu.
Sebelum itu. Mungkin ada yang tak pasti macam mana nak setup environment untuk menjalankan aktiviti ini? Ikut langkah di bawah
- Pastikan anda ada account google (gmail, gdrive)
- Login ke Google Colab
- Klik New Notebook
- Copy-paste kod di bawah
- Klik kod pada cell notebook
- Klik simbol start di bahagian atas kiri cell
Sila lihat screenshot seperti di bawah.
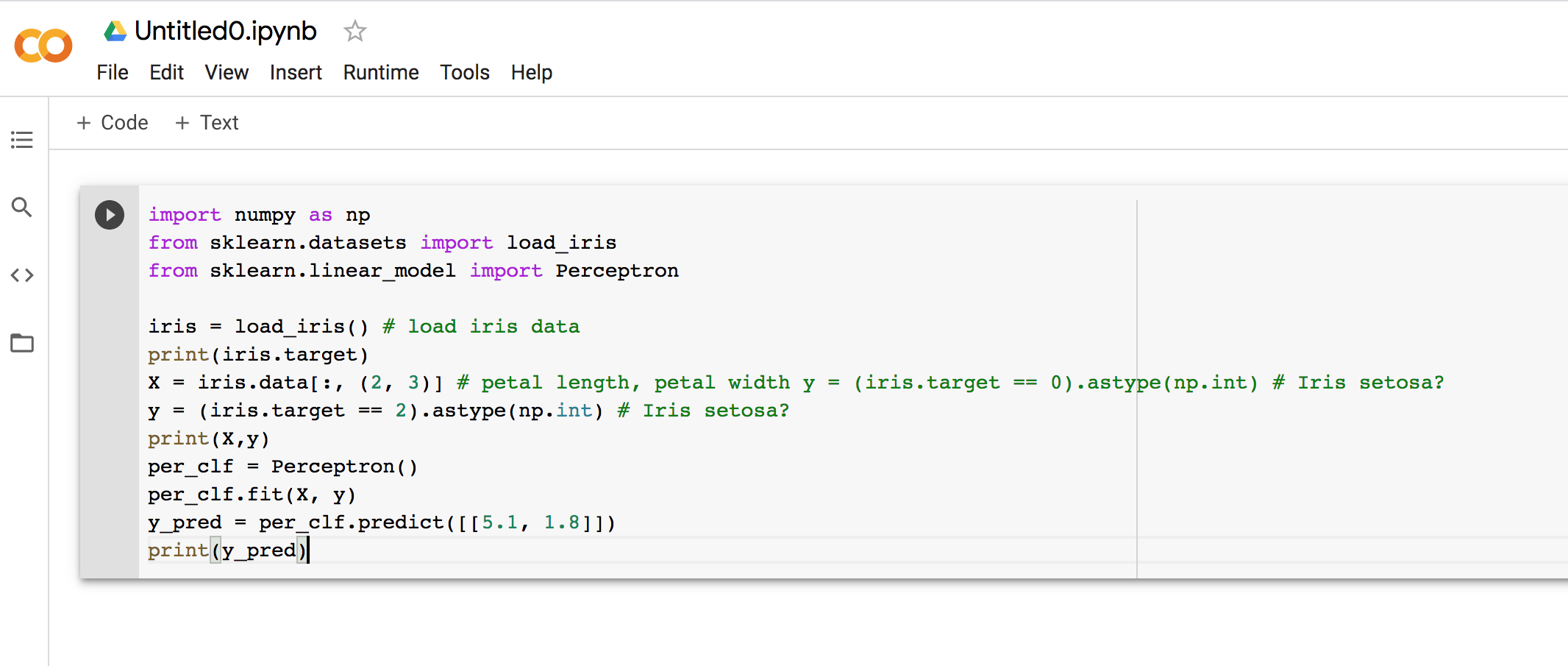
Apa yang anda perlu buat dengan kod ini? Anda cuma perlu tekan butang run sahaja. Kemudian cubalah baca komen-komen di "#", yang telah saya coretkan pada kod tersebut untuk memahami fungsinya. Cuba main-main dengan kod itu. Jangan takut, tukarlah apa-apa sahaja yang tercetus di hati anda.
"Belajar melalui pengalaman, Belajar melalui kesilapan"
import numpy as np
# 1. Kita guna IRIS data download daripada sklearn library
# Apa itu IRIS Data:-> https://en.wikipedia.org/wiki/Iris_flower_data_set
# 2. Kita guna Perceptron daripada library sklearn (kita tak guna KERAS Tensorflow atau Pytorch buat masa ini)
from sklearn.datasets import load_iris
from sklearn.linear_model import Perceptron
# 3. Kita guna jer function load_iris untuk download IRIS data ke variable iris
iris = load_iris()
# 4. Uncomment ni kalau nak paparkan iris data. Iris data ada 4 input fitur
#print(iris.data)
# 5. Uncomment ni kalau nak paparkan iris target label. Iris data ada 3 target label klas (0,1,2)
# 0->Setosa, 1->Versicolor, 2->Virginica : (perceptron hanya boleh klasifikasi 2 klas sahaja)
#print(iris.target)
# 6. Untuk contoh ini, kita cuma guna 2 input fitur sahaja daripada iris data
# ":" bermaksud ambil semua row, (2,3) bermaksud ambil fitur column element ke 3 dan 4 sahaja (ingat array index bermula dari 0)
# Iaitu fitur: 3->petal length, 4->petal width
X = iris.data[:, (2, 3)]
# Tukarkan klas 0->1, 1 dan 2->0 (Tukar kepada Klas Binary (1,0) untuk kegunaan Perceptron)
# 1->Setosa atau 0->Bukan Setosa
y = (iris.target == 0).astype(np.int) # Iris setosa?
#7. Uncomment untuk lihat hasil penukaran data
#print(X)
#print(y)
#Cipta Perceptron Neuron
per_clf = Perceptron()
#Train Model Perceptron dengan Data input X dan Data Target Label y
per_clf.fit(X, y)
#Gunakan model untuk membuat ramalan klasifikasi menggunakan Test Data [5.1,1.8]
y_pred = per_clf.predict([[5.1, 1.8]])
#Paparkan Hasil Prediksi (1->Setosa atau 0->Bukan Setosa)
print(y_pred)
Ok. Saya rasa kita berhenti di sini dahulu. Untuk artikel seterusnya, saya akan cuba untuk mengimplementasikan satu contoh lengkap penggunaan perceptron bagi tujuan klasifikasi binari.
Assalamualaikum dan InsyAllah kita bertemu lagi.